A domain is a discrete structural unit that is assumed to fold independently of the rest of the protein and to have its own function. It can be composed of 20 or so amino acid residues to up to hundreds of them. Domains are made up of multiple secondary structure units (alpha helices, beta sheets, etc.) Most proteins are multi-domain. Folds are the core 3-D structures of domains. It is believed that only a few thousand folds exist. A beta-barrel is an example of a fold.
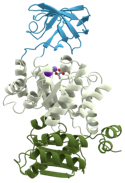 Protein domains
Protein domains Motifs are short, conserved regions and frequently are the most conserved regions of domains. Motifs are critical for the domain to function - in enzymes, for example, they may contain the active sites. Another example of motifs would be nuclear localization sequences. More specifically, a motif in biology is a mathematical model, typically of a sequence, which is predictive of which sequences to some defined group. For example, a DNA sequence motif can characterize the binding site of a transcription factor, i.e. which sequences tend to be bound by this factor. For proteins, sequence motifs can characterize which proteins (protein sequences) belong to a given protein family. A simple motif could be, for example, some pattern which is strictly shared by all members of the group, e.g. WTRXEKXXY (where X stands for any amino acid). There are also more complex motif models.
 Structural motif
Structural motifA pattern describes a short, contiguous stretch of protein using regular expressions. E.g., DX[DE]X is a pattern composed of amino acid D, followed by any, followed by either D or E, followed by any.
A profile is built by multiple sequence alignment, and is a matrix or table that describes the probability of finding a particular amino acid at a certain position. Mathematical means such as hidden Markov models are used to generate profiles.
A repeat is a stretch of amino acid sequence that gets repeated a number of times along the length of the sequence. There usually is some sequence variation between the repeated segments. Many domains are constituted from repeats.
List of protein domains